GRPO and DeepSeek-R1-Zero
📚 Table of Contents
- 🔍 DeepSeek-R1-Zero: Why and What?
- 🏗️ DeepSeek-R1-Zero Model Architecture
- 🚀 DeepSeek-R1-Zero Training: GRPO
- ⚖️ Advantages and Disadvantages
- 🥊 GRPO vs PPO
🔍 DeepSeek-R1-Zero: Why and What?
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
What is DeepSeek-R1-Zero?
DeepSeek-R1-Zero is a cutting-edge large language model (LLM) developed by DeepSeek, a AI research company. What makes it stand out is its unique training method. While most language models rely heavily on supervised fine-tuning (SFT), where they learn from labeled datasets provided by humans, DeepSeek-R1-Zero takes a different approach. It starts with a pretrained model, DeepSeek-V3, and instead of using supervised fine-tuning, it undergoes large-scale training exclusively through reinforcement learning (RL).
In reinforcement learning, the model learns by interacting with an environment and receiving feedback in the form of rewards or penalties. This process is similar to teaching through trial and error: the model generates responses, evaluates their quality, and adjusts its behavior to improve future outcomes. Over time, this helps the model figure out what kinds of answers are more accurate or useful, without needing explicit examples for every situation.
By relying solely on reinforcement learning after pretraining, DeepSeek-R1-Zero naturally develops powerful reasoning abilities. It can self-verify its answers, reflect on previous outputs to improve over time, and build detailed, step-by-step explanations through extended chain-of-thought (CoT). This approach allows the model to think more critically and flexibly, even without the structured guidance that supervised learning typically provides.
Why develop DeepSeek-R1-Zero?
The authors highlight that their reinforcement learning technique, GRPO, performed exceptionally well in DeepSeekMath and Math-shepherd. However, both models still relied heavily on Supervised Fine-Tuning (SFT) data, which is time-consuming to collect. To address this, they explored whether a model with reasoning capabilities could be developed purely through reinforcement learning, eliminating the need for SFT (Supervised Fine-Tuning) data altogether.
“explore the potential of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure reinforcement learning process.” — DeepSeek-R1 (DeepSeek-R1-Zero) technical report
Building and training DeepSeek-R1-Zero gave authors insights into refining the process to develop a better reasoning model DeepSeek-R1.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
🏗️ DeepSeek-R1-Zero Model Architecture
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
What is DeepSeek-R1-Zero’s model architecture?
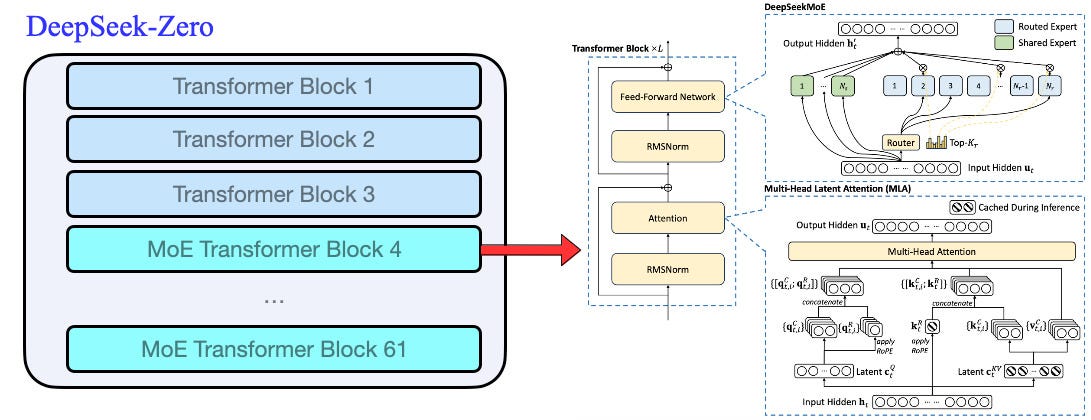
The model architecture of DeepSeek-R1-Zero and DeepSeek-R1 is derived from DeepSeek-V3-Base. Please refer to my DeepSeek-R1: Model Architecture article to understand the model architecture in depth.
What is the input to the model?

This template requires DeepSeek-R1-Zero to first produce a reasoning process, followed by the final answer.
Why use this template?
“We intentionally limit our constraints to this structural format, avoiding any content-specific biases — such as mandating reflective reasoning or promoting particular problem-solving strategies — to ensure that we can accurately observe the model’s natural progression during the RL process.” — DeepSeek-R1-Zero/R1 technical report
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
🚀 DeepSeek-R1-Zero Training: GRPO
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
How is DeepSeek-R1-Zero trained?
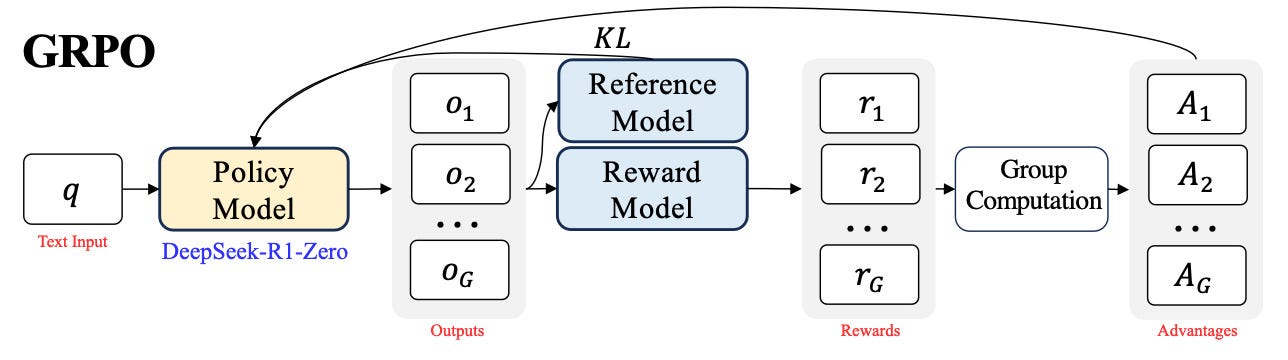
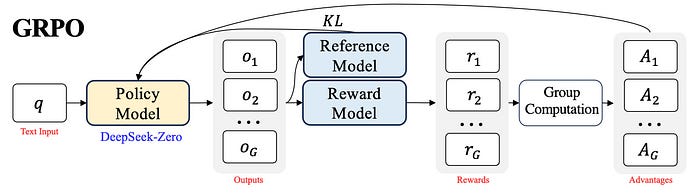
It is trained using Reinforcement technique called as Group Relative Policy Optimization (GRPO).
What is GRPO?
Group Relative Policy Optimization (GRPO) is a reinforcement learning (RL) technique developed by DeepSeek to enhance the reasoning capabilities of large language models (LLMs).
GRPO builds upon the Proximal Policy Optimization (PPO) framework by introducing a group-based approach, where multiple model responses are generated for a given prompt. These responses are then comparatively evaluated within the group, allowing the model to learn more effectively from its own outputs. This method enables the model to self-improve by assessing and ranking its responses, leading to more coherent and accurate outputs.
The GRPO vs PPO details are covered in later sections.
How is GRPO computed?

This looks scary, but isn’t. When we look at each term it will be clear what it is and how it works.
The advantage A_i calculations

Formally, for each question or input prompt 𝑞, a group of outputs {𝑜1, 𝑜2, · · · , 𝑜𝐺 } are sampled from the old policy model 𝜋_𝜃_𝑜𝑙𝑑 .
A reward model is then used to score the outputs, yielding 𝐺 rewards, r = {𝑟1, 𝑟2, · · · , 𝑟𝐺 } correspondingly.
The reward model calculates reward based on rules. The DeepSeek-Zero calls this ‘rule-based reward’.
Subsequently, these rewards are normalized by subtracting the group average and dividing by the group standard deviation.
These normalized reward at the end of each output 𝑜_𝑖 are the advantages 𝐴_𝑖.
What are these rule-based rewards?

Why use advantage (A_i) instead of directly using reward (r)?
Advantage subtracts the baseline (baseline is average reward in GRPO and V(s)-value function in PPO) from the total reward to reduce variance. This makes learning more stable and efficient. Raw rewards can have high variance, making it harder for the model to distinguish whether an action was truly better or just lucky.
Benefits of calculating advantage (A_i) the way GRPO equation 3 calculates it?
In Group Relative Policy Optimization (GRPO), the advantage term serves additional purposes beyond just variance reduction.
Here’s how:
I. Relative Performance Evaluation (Key Purpose in GRPO):
In GRPO, the advantage A_i is computed by comparing an individual response’s reward to the mean reward of a group of responses for the same input prompt. This introduces a relative evaluation mechanism:
- Purpose: Instead of just learning from absolute rewards, the model learns which responses are better than others in the same context.
- Benefit: This encourages the model to generate responses that consistently outperform the average, fostering more nuanced, high-quality outputs.
II. Implicit Reward Normalization:
Because the advantage is calculated relative to the group’s mean reward, this acts as a form of dynamic reward normalization:
- Purpose: It adjusts for fluctuations in the reward scale across different prompts.
- Benefit: This ensures that learning signals are balanced across diverse prompts, preventing any single prompt from dominating the learning process.
III. Encouraging Diversity in Outputs:
By evaluating outputs relative to each other within a group, GRPO can help promote diverse exploration:
- Purpose: The model is rewarded not just for correctness but for producing distinct, better-than-average responses.
- Benefit: This can lead to more creative or varied outputs in generative tasks, as the model avoids converging on repetitive or mediocre answers.
IV. Simplification of the Value Function:
Unlike traditional RL approaches that require an explicit value function to estimate expected returns, GRPO uses the group mean reward as a simpler, implicit baseline:
- Purpose: This removes the need for complex value function approximation.
- Benefit: It reduces computational complexity while maintaining effective learning signals.
KL Divergence calculations:
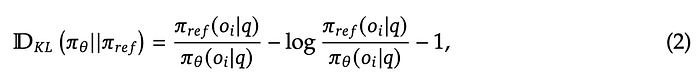
“Instead of adding KL penalty in the reward, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the objective function, avoiding complicating the calculation of 𝐴_𝑖.” — DeepSeekMath
KL Divergence in Reinforcement Learning:
- KL Divergence measures how one probability distribution differs from another. In RL, it’s often used to compare the new policy with the old policy. It helps ensure that updates don’t make the policy change too drastically, maintaining stability.
PPO (Proximal Policy Optimization):
- PPO adds a KL penalty directly into the reward function. This means it modifies the reward signal based on how much the new policy diverges from the old one. However, this approach complicates the calculation of the advantage function A_i because the modified reward changes how advantages are estimated.
GRPO (Group Relative Policy Optimization):
- GRPO, instead of penalizing the reward, adds the KL divergence directly to the objective function as a regularizer. This means it optimizes the policy with the KL divergence acting like a constraint, but it doesn’t interfere with the reward or advantage calculations.
- This keeps the advantage estimation simpler while still controlling the policy updates.
Why use different formulation of KL divergence in DeepSeek-R1-Zero?
Problem with Standard Estimation in RL:
- When applying RL algorithms like Proximal Policy Optimization (PPO), we estimate KL divergence between the old policy and the new policy using samples.
- The sample-based estimator can fluctuate due to finite sample sizes, sometimes yielding negative values, which contradicts the theoretical non-negativity of KL divergence.
- Even if the values are positive, they may be biased, meaning they systematically deviate from the true divergence.
Schulman’s Unbiased Estimator:
- Schulman introduced a more robust estimator designed to correct this bias and ensure the KL divergence remains non-negative in practice.
- This estimator adjusts how the divergence is calculated from the sampled data, making it more reflective of the true KL divergence, even in the presence of sample noise.
- The method leverages techniques like importance sampling and variance reduction to improve estimation accuracy.
We will understand what is π_θ and π_ref in next section or subtopic.
Objective function calculations:
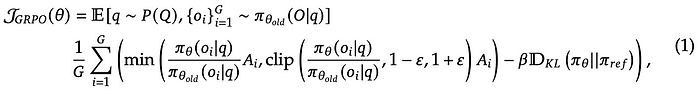
Let’s understand each term in this equation:
Probability ratio:
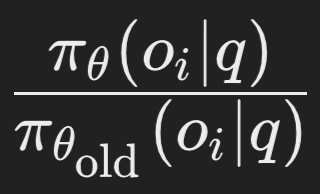
- This is the probability ratio between the new policy (π_θ) and the old policy (π_θ_old) for the output o_i given the query (input prompt) q.
- Interpretation: It measures how much the new policy deviates from the old one.
- Calculation: You compute this by evaluating the probability of the output o_i under both the new and old policies and taking their ratio.
What is the ‘policy’?
In Reinforcement Learning (RL), a policy is a function that maps states (or inputs) to actions (or outputs). In the context of Large Language Models (LLMs), the policy corresponds to the probability distribution over the next token given a prompt or sequence of tokens.
- LLM as a Policy:
When we say policy in context of LLMs, we are referring to the LLM model itself, which predicts the next token probabilities based on the input (prompt). So, in this case, the LLM model is the policy.

What Exactly Are the New and Old Policies During Training?
New Policy:
- This is the current model being updated during training. After each optimization step (or a batch of steps), the parameters θ are adjusted based on the computed gradients.
Old Policy:
- This is a frozen snapshot of the model parameters from a previous point in training.
- It serves as a stable reference to compare against the new policy to prevent drastic changes.
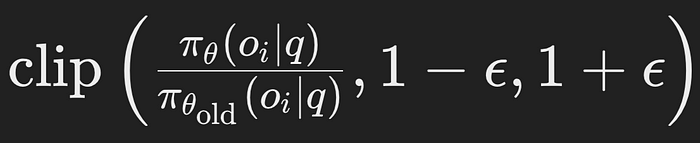
- The clip function restricts the probability ratio within the range [1−ϵ,1+ϵ].
- Purpose: This prevents the policy from making large, destabilizing updates. It ensures that the ratio does not move too far from 1, thus keeping the new policy close to the old one.
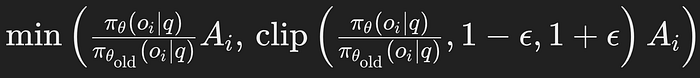
- This expression ensures that the objective function benefits from the clipped ratio only when it leads to conservative updates.
- Purpose: By taking the minimum of the unclipped and clipped values, the algorithm prevents overly optimistic updates that could lead to policy degradation.
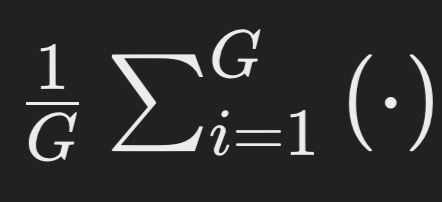
- This is the average over G outputs from a single input prompt.
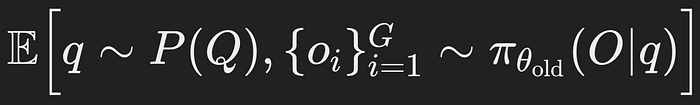
- This denotes the expectation over the distribution of queries q (input prompts) and the old policy’s outputs o_i.
More detailed equation provided in DeepSeekMath if you want to explore more:
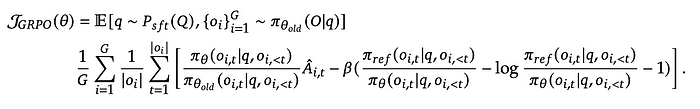
Gradient updates with GRPO:
GRPO objective function and gradient equation are provided in the DeepSeekMath:
Objective function:
Gradient equation:
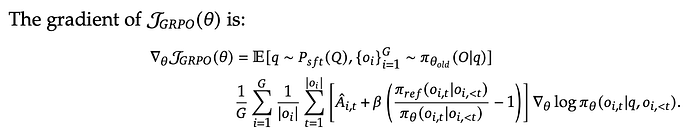
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
⚖️ Advantages and Disadvantages:
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Advantages:
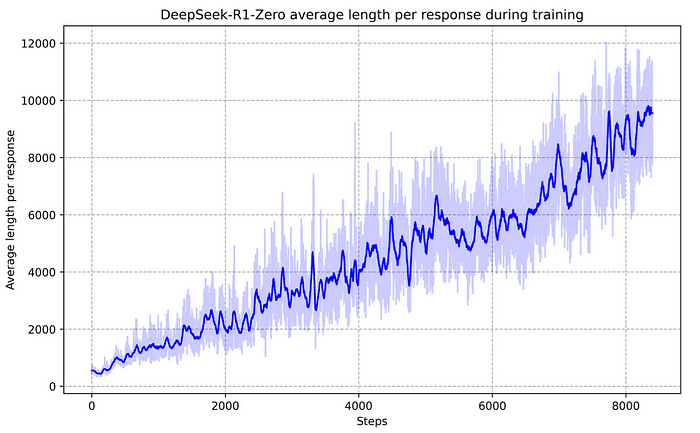
As it is trained more, it generates more tokens to think more and generate accurate outputs.
Complex reasoning abilities developed:
“This improvement is not the result of external adjustments but rather an intrinsic development within the model. DeepSeek-R1-Zero naturally acquires the ability to solve increasingly complex reasoning tasks by leveraging extended test-time computation.” — DeepSeek-R1-Zero/R1 technical report.
Self-reflection during generation emerged:
“Behaviors such as reflection — where the model revisits and reevaluates its previous steps — and the exploration of alternative approaches to problem-solving arise spontaneously. These behaviors are not explicitly programmed but instead emerge as a result of the model’s interaction with the reinforcement learning environment.”
Disadvantage:
“Drawback of DeepSeek-R1-Zero: Although DeepSeek-R1-Zero exhibits strong reasoning capabilities and autonomously develops unexpected and powerful reasoning behaviors, it faces several issues. For instance, DeepSeek-R1-Zero struggles with challenges like poor readability, and language mixing. To make reasoning processes more readable and share them with the open community, we explore DeepSeek-R1, a method that utilizes RL with human-friendly cold-start data.” — DeepSeek-R1-Zero/R1 technical report.
What data is used specifically in RL stage?
The data is not open-sourced.
But typically SFT (supervised-finetuning) input prompts/queries can be used. But they will be used in a specific input format as below for DeepSeek-R1-Zero RL training.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
GRPO vs PPO
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Difference visualized
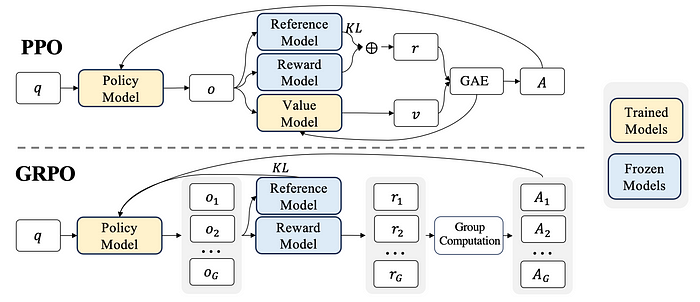
Why use GRPO instead of PPO?

Does the ‘group’ in GRPO makes sense?
“The group relative way that GRPO leverages to calculate the advantages, aligns well with the comparative nature of rewards models, as reward models are typically trained on datasets of comparisons between outputs on the same question” — DeepSeekMath
— — — — — — — — — — — — — — — — — — — — — — — — — — — — —
I have written this article in a Question-and-Answer format which I like and helps to understand the concepts in depth. Hopefully this is useful to everyone.
References:
YouTube Video: https://www.youtube.com/watch?v=QdEuh2UVbu0

